阿里二面挂了!问 “1 亿日活怎么算”,我答 “HyperLogLog”,面试官:你要把大屏搞崩 吗?
原文地址
在45岁老架构师尼恩的读者交流群(50+人)里,最近不少老铁拿到了阿里、滴滴、极兔、有赞、希音、百度、字节、网易、美团这些一线大厂的面试入场券,恭喜各位!
前两天就有个小伙伴面阿里, 在阿里二面中,针对“5亿用户,1亿日活,需精准展示大屏并判断单用户登录”的场景,仅回答使用HyperLogLog,导致面试失败。
核心教训:技术选型不能只记优点,必须严格适配具体场景的核心诉求。
面试场景:面试官提出需同时满足“实时大屏展示”和“精准判断单用户登录”两个硬性诉求。
错误回答:回答“HyperLogLog”,仅考虑其省内存(12KB)的优点。
面试官质疑点:
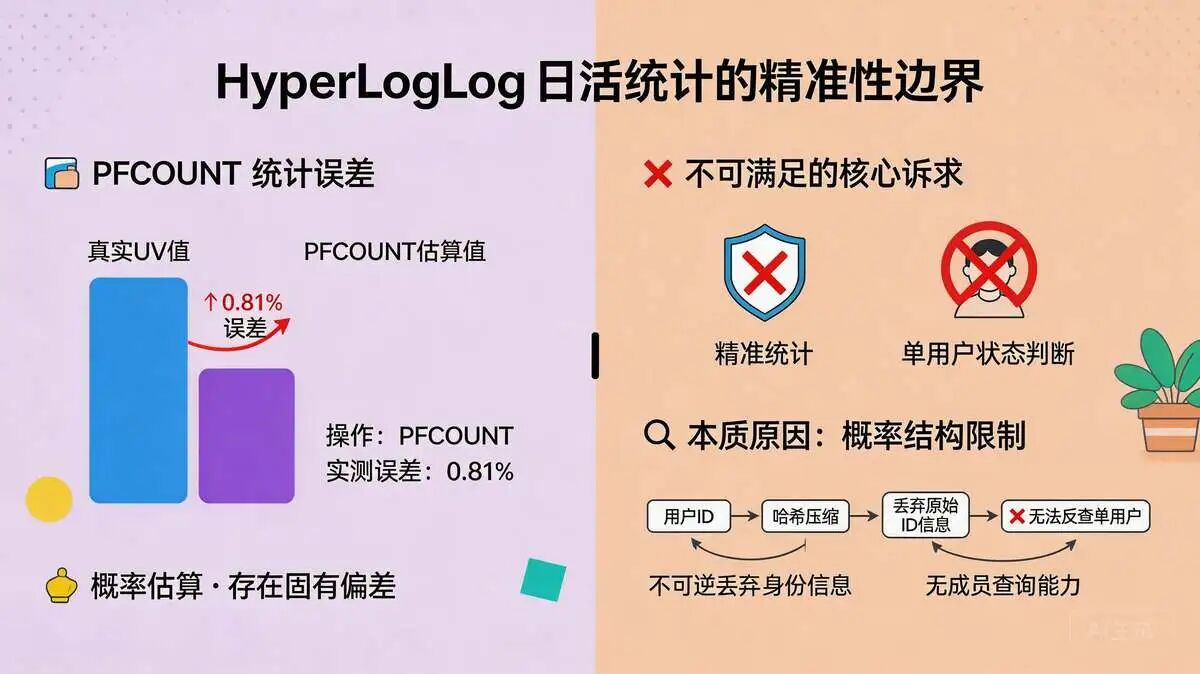
- HyperLogLog有0.81%的理论误差,1亿日活误差达81万,无法满足精准展示。
- HyperLogLog无法提供判断单个用户是否登录的命令。
小伙伴 没有看过系统化的 答案,回答也不全面 ,so, 面试官不满意 , 面试挂了。
小伙伴找尼恩复盘, 求助尼恩。
这里尼恩给大家做一下 系统化、体系化的梳理,使得大家可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”。
同时,也一并把这个题目以及参考答案,收入咱们的 《尼恩Java面试宝典PDF》V176版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
最新《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请关注本公众号【技术自由圈】获取,后台回复:领电子书
2. 戳穿“想当然”的陷阱:HyperLogLog不是万能的
2.1 HyperLogLog计算大屏日活的实操demo
这个demo暴露HyperLogLog两个致命问题:
-
统计结果有误差,无法满足大屏精准展示需求;
-
无法判断单个用户是否登录,直接违背核心诉求。
HyperLogLog核心命令:仅PFADD(添加)、PFCOUNT(统计)、PFMERGE(合并)。
| 命令 | 功能 | 关键说明 |
|---|---|---|
PFADD |
添加元素 | 语法:PFADD key element [element ...],支持批量向指定 HyperLogLog 键中添加用户 ID 等元素,是统计的基础操作 |
PFCOUNT |
统计基数 | 语法:PFCOUNT key [key ...],返回指定 HyperLogLog 中不重复元素的估算数量(存在约 1% 左右误差),是日活统计的核心查询命令 |
PFMERGE |
合并多个 HyperLogLog | 语法:PFMERGE destkey sourcekey [sourcekey ...],可将多个 HyperLogLog 合并为一个(比如合并多日的日活数据统计周活 / 月活) |
HyperLogLog 统计日活的缺陷:
- 使用
PFCOUNT统计日活,结果存在误差(示例中1亿统计为约9921万)。 - 尝试使用
PFEXISTS判断单用户状态,但该命令不存在。
结论:HyperLogLog无法满足“精准统计”和“单用户状态判断”两大核心诉求。
尼恩提示:此文是精简版,完整版本,请参考 尼恩 免费百度网盘 免费pdf
2.2 HyperLogLog的误差账,算清楚就知道不能用
HyperLogLog的 决定了HyperLogLog的适用场景:
- 只能用于“非精准、只看趋势”的场景(如全网访问量统计、临时大盘兜底)
- 绝对不能用于阿里核心业务的精准日活统计。
理论误差率:固定为0.81%。
误差影响量化:1亿日活 → 误差范围±81万(即9919万~10081万之间波动)。
业务影响:
- 导致运营误判活动效果。
- 引发基于错误数据的资源分配决策。
- 业务方无法信任大屏数据。
最终结论:HyperLogLog不适用于对数据精准性要求高的核心业务场景。
3. 精准日活统计的 基础方案:使用 Bitmap
3.1 Bitmap实现精准判断用户登录状态的demo
Bitmap底层基于Redis String实现,核心逻辑很简单:通过“bit位”标记用户状态(1=登录,0=未登录),用户ID作为bit偏移量。
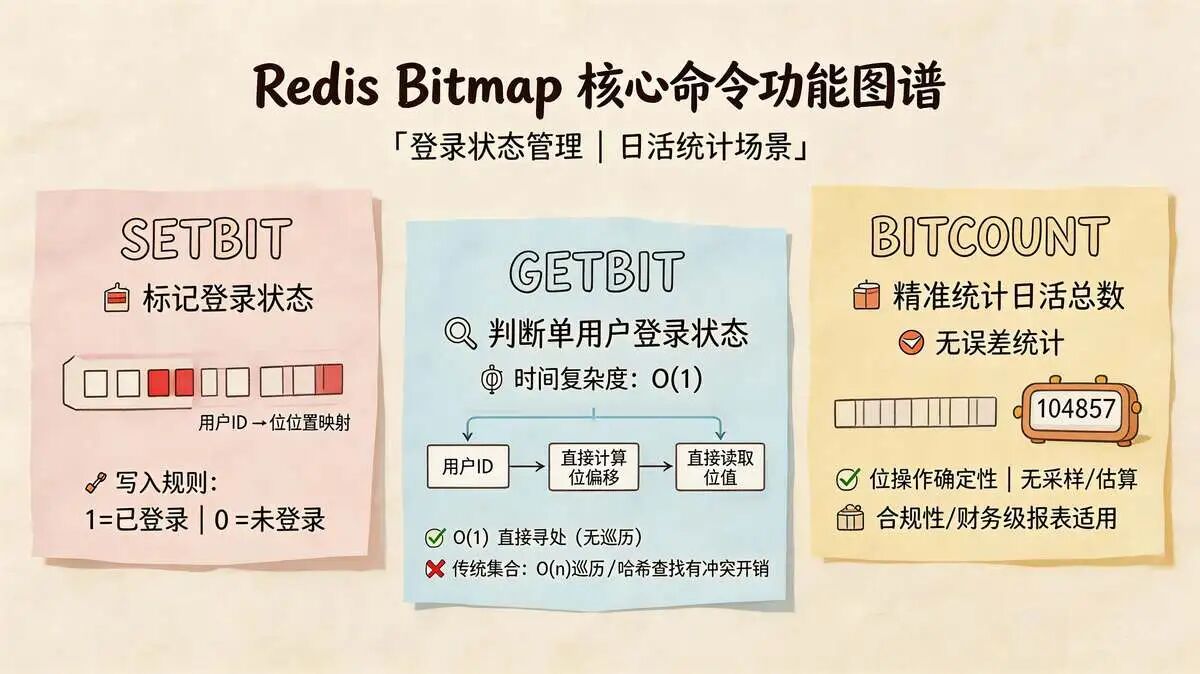
Bitmap核心命令与功能:
SETBIT:标记用户登录状态。GETBIT:判断单用户是否登录,O(1)时间复杂度。BITCOUNT:精准统计日活总数,无误差。
Bitmap 核心命令主要是 位设置、位查询、位统计三类, 可以 完美实现 精准统计 + 单用户状态判断的业务诉求,具体如下:
| 命令名称 | 核心功能 | 语法示例 | 关键特点 |
|---|---|---|---|
SETBIT |
设置指定偏移量的比特位值 | SETBIT bitmap:dau:20260313 100001 1 |
1 = 标记用户登录,0 = 标记未登录;返回值为该位原本的数值(0/1);时间复杂度 O (1) |
GETBIT |
查询指定偏移量的比特位值 | GETBIT bitmap:dau:20260313 100001 |
返回 1 = 用户已登录,返回 0 = 未登录;毫秒级响应,是判断单用户状态的核心命令 |
BITCOUNT |
统计指定 Key 中值为 1 的比特位总数 | BITCOUNT bitmap:dau:20260313 |
精准统计无误差,是日活大屏展示的核心操作;支持指定字节范围统计(可选参数) |
优势:完美满足“精准判断”和“无误差统计”两大诉求。
内存计算(连续ID):5亿用户(注册用户数)的Bitmap约需60MB核心内存(加元数据约65MB)。
尼恩提示:此文是精简版,完整版本,请参考 尼恩 免费百度网盘 免费pdf
3.2 Bitmap “精细化分片”, 解决big key问题
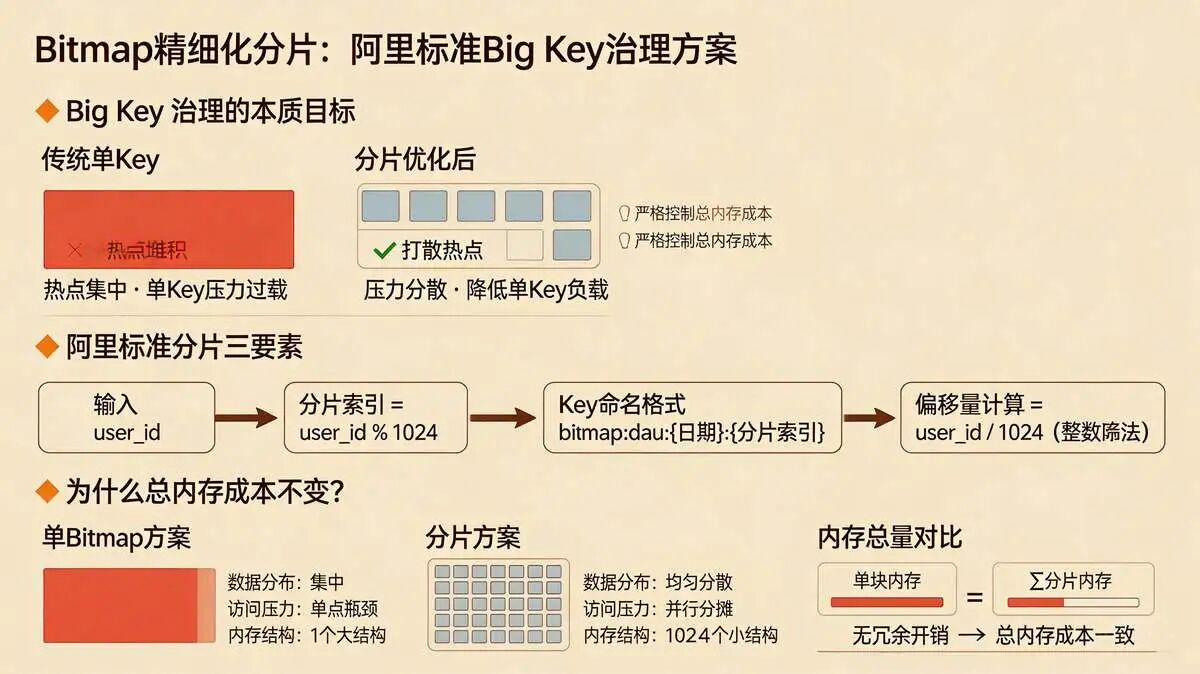
核心思路只有一个:“将单个大Bitmap拆分为多个小Bitmap,打散热点、降低单Key压力”,同时严格控制总内存成本。
核心问题:单一大Bitmap存在“大Key”风险和高并发下单点压力。
分片方案(阿里标准):
- 分片规则:
分片索引 = user_id % 1024。 - Key命名:
bitmap:dau:{日期}:{分片索引}。 - 偏移量计算:
偏移量 = user_id / 1024(整数除法)。
分片优势:
- 热点打散:1024个分片可分布到Redis Cluster不同节点。
- 内存可控:单个小Bitmap仅63KB,总内存仍为65MB。
- 故障隔离:单个分片异常不影响整体。
- 统计灵活:支持按分片统计。
4. 大厂工业级方案:分层 + 分片 + 多方案融合
核心目标:满足“精准判断用户是否登录”的核心诉求,同时解决单Key Bitmap的“单点热点”问题。
4.1 核心层:Bitmap 分片 解决单Key “ 热点”问题
分片规则:
用户ID按user_id % 1024拆分到1024个Bitmap Key,Key命名:bitmap:dau:20260313:{0~1023}。
目标:精准判断单用户状态,并解决高并发压力。
落地细节:
- 过期策略:日级Key设置24小时自动过期,避免内存堆积。
- 性能优化:高并发下使用
pipeline进行批量SETBIT操作。 - 监控与扩容:监控分片QPS,异常时自动扩容分片数。
4.2 大屏层: Bitmap 预计算 解决统计时遍历耗时 问题
目标:解决实时BITCOUNT遍历1024个分片可能带来的延迟问题。
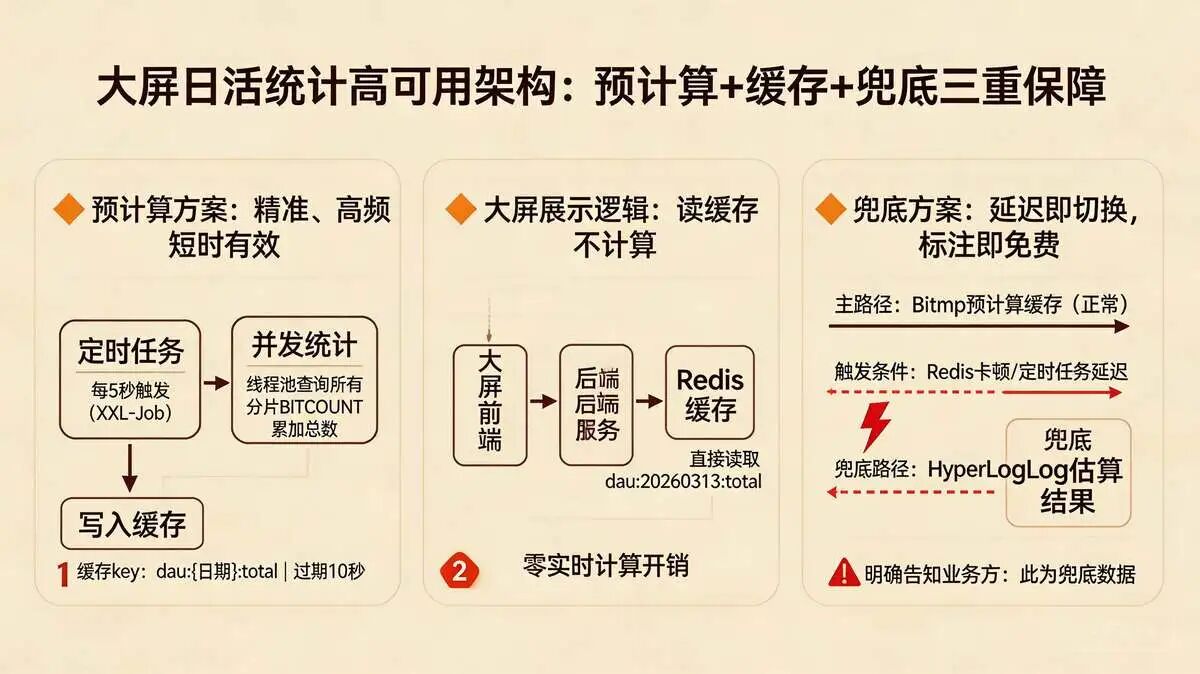
1、预计算方案:
- 定时任务:使用XXL-Job等,每5秒触发一次。
- 并发统计:用线程池并发查询所有分片的
BITCOUNT。 - 结果缓存:将累加得到的精准日活总数存入缓存(如
dau:{日期}:total),设置短时过期(如10秒)。
兜底方案:若预计算延迟,临时用HyperLogLog的估算结果展示(需明确告知业务方此为兜底数据)。
2、大屏展示逻辑:
大屏后端接口直接读取缓存Keydau:20260313:total,无需实时计算,响应时间 < 1ms,完全满足大屏实时展示需求;
3、 兜底方案(阿里高可用设计必备):
若定时任务延迟(如Redis集群卡顿),大屏临时读取HyperLogLog的统计结果(误差率0.81%)作为兜底,待精准数据计算完成后自动切换——既保证高可用,又尽量减少误差对业务的影响。
尼恩提示:此文是精简版,完整版本,请参考 尼恩 免费百度网盘 免费pdf
5. 多维聚合场景:使用 Bitmap + ClickHouse 完成多维度统计
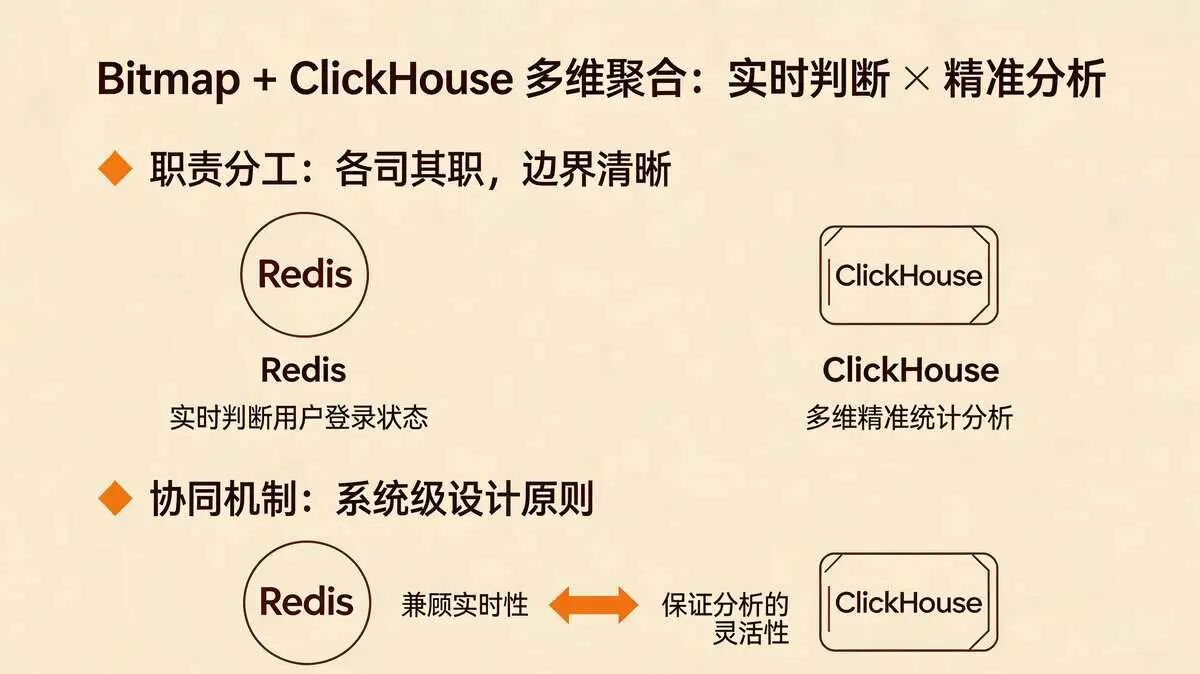
核心思路很简单:
- Redis负责“实时判断用户登录状态”
- ClickHouse负责“多维精准统计分析”
- 两者协同工作,既兼顾实时性,又保证分析的灵活性。
问题场景:需要统计如“杭州地区、iOS系统、90后”等多维度组合的精准日活。
分层架构:
- 实时层:Redis分片Bitmap记录用户登录状态。
- 数据管道:用户登录日志(含多维标签)实时写入Kafka,由Flink消费清洗。
- 分析层:清洗后数据写入ClickHouse,利用其原生的Bitmap数据类型及函数(如
bitmapAnd,bitmapCount)进行高效的多维交集统计。
技术优势:ClickHouse的Bitmap函数针对海量数据聚合优化,亿级数据秒级返回结果。
适用场景:满足业务侧复杂的用户分群、多维漏斗分析等需求。
6.绝命追问:稀疏id(如雪花id)用Bitmap, 有什么坑?
6.1 稀疏id(如雪花id)用Bitmap的核心问题
Bitmap的内存大小取决于“最大用户ID”,而非“实际登录用户数”。
雪花ID特点:非连续、数值极大(64位,最大约9e18)。
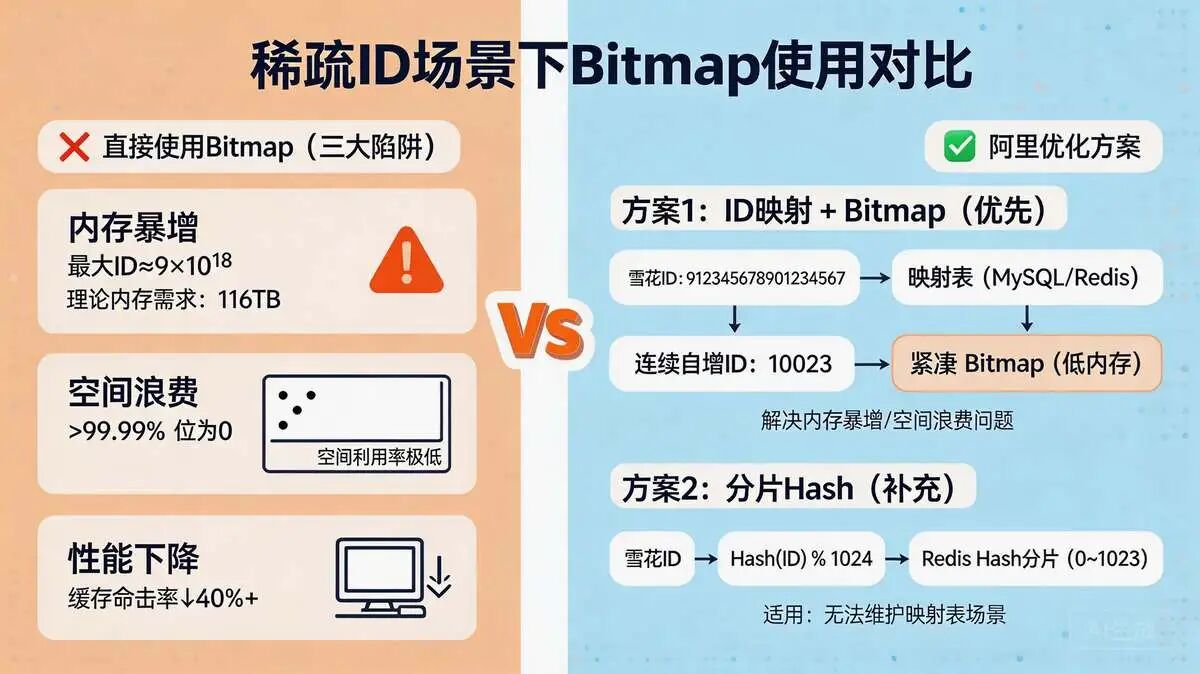
直接使用Bitmap的三大坑:
- 内存暴增:最大ID可能达9e18,理论需约116TB内存,完全不可接受。
- 空间浪费:ID稀疏导致绝大部分bit位为0,空间利用率极低。
- 性能下降:超大Bitmap操作会导致缓存命中率下降,延迟增加。
6.2 稀疏id(如雪花id)用Bitmap的解决方案
针对雪花ID等稀疏ID,阿里实际落地中常用两种解决方案,优先选择方案1(兼顾精准性和成本),方案2则作为补充(适合无法维护映射表的极端场景)。
方案1:ID映射 + Bitmap(优先方案)
- 核心思路:维护“雪花ID → 连续自增ID”的映射表(存于MySQL/Redis)。
- 操作流程:用户登录时,先查映射表得到连续ID,再用该ID作为Bitmap偏移量。
- 内存成本:1亿用户仅需约12MB,成本极低。
- 适用场景:新系统或可改造的核心业务,追求长期成本最优。
方案2:分片Hash(补充方案)
- 核心思路:放弃Bitmap,使用Redis Hash。对雪花ID哈希后取模分片(如1024片),将ID作为Field存储。
- 核心操作:
HSET记录登录,HEXISTS判断状态,累加各分片HLEN得到总数。 - 内存成本:1亿用户约3.7GB(理论值),生产优化后约2-3GB。
- 适用场景:历史老旧系统无法改造、临时需求、边缘业务。
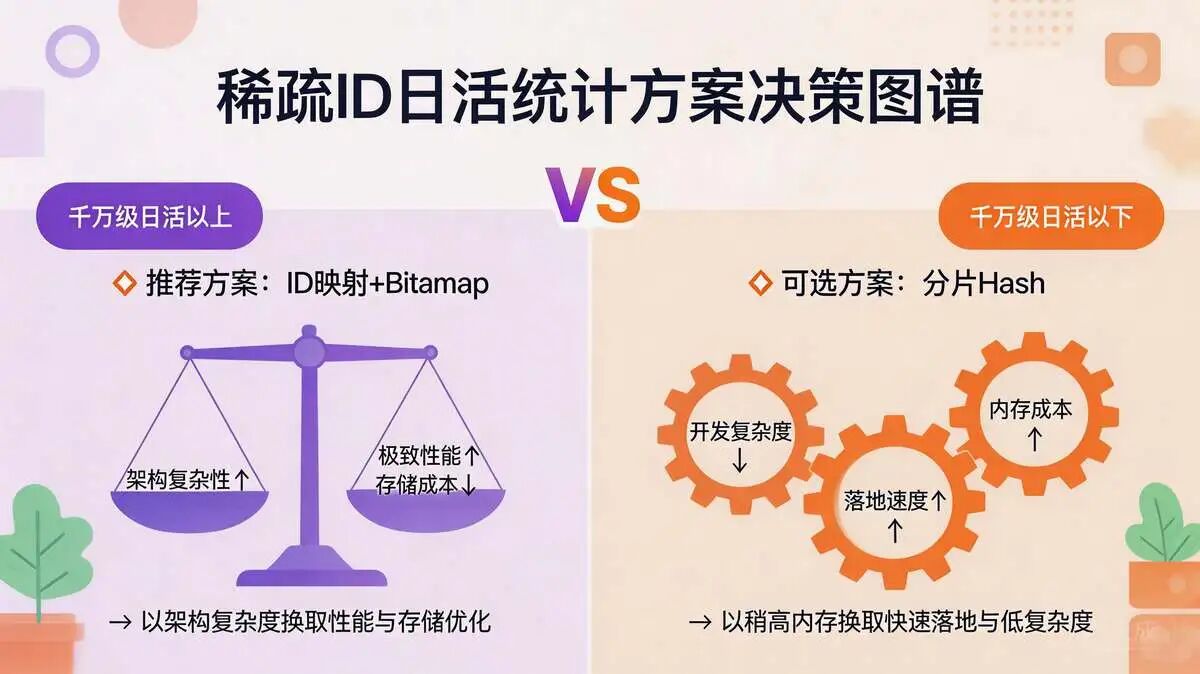
方案选择对比
- 千万级日活以上:优先ID映射+Bitmap。用架构复杂性换取极致的性能和存储成本。
- 千万级日活以下:可选分片Hash。用稍高的内存成本换取更低的开发复杂度和更快的落地速度。
尼恩提示:此文是精简版,完整版本,请参考 尼恩 免费百度网盘 免费pdf
7. 面试标准答案模板:阿里架构师级回答
阿里的Redis面试题,从来不是考察“你记不记得API”,而是考察“你懂不懂业务场景,能不能在成本、精准度、性能之间找到平衡”。
一、先破题(否定单一方案):
- 明确点出HyperLogLog的误差(0.81%)和功能缺失(无法判断单状态),声明其不适用。
- 提出核心思路:采用 “分层 + 分片 + 多方案融合” 的架构。
二、核心层(分片Bitmap解决精准与并发):
- 基础逻辑:Bitmap的
SETBIT/GETBIT/BITCOUNT命令满足精准诉求。 - 分片设计:按
user_id % 1024分片,计算offset = user_id / 1024。 - 大屏优化:通过定时预计算+缓存(如
dau:date:total)实现毫秒级响应,HyperLogLog作兜底。
三、进阶层(多维聚合用ClickHouse):
- 分层架构:Redis(实时状态) + Kafka/Flink(数据同步) + ClickHouse(多维分析)。
- 技术选型:利用ClickHouse原生的Bitmap函数进行高效多维聚合查询。
四、追问层(稀疏ID解决方案):
- 指出问题:雪花ID直接用Bitmap会导致内存暴增(116TB)、空间浪费、性能下降。
- 给出方案:
- 优先方案:维护 “雪花ID → 连续ID”映射表,再用Bitmap。
- 补充方案:使用 分片Hash(
hash(id)%1024)。
- 场景取舍:
- 千万级日活以上:选 ID映射+Bitmap(成本最优)。
- 千万级日活以下:可选 分片Hash(开发成本低)。
五、总结(架构原则):
- 核心是 “按诉求分层、按数据分片、按场景融合”。
- 所有设计围绕 “精准性、性能、成本” 三大核心进行权衡。
8. 写在最后
方案对比与选型核心:
- HyperLogLog:省内存,但牺牲精准度和单状态判断能力,只适合非精准场景。
- 单Key Bitmap:精准,但扛不住高并发,且对稀疏ID不友好。
- 分片Bitmap + 预计算 + 多引擎融合:是满足阿里级业务需求的
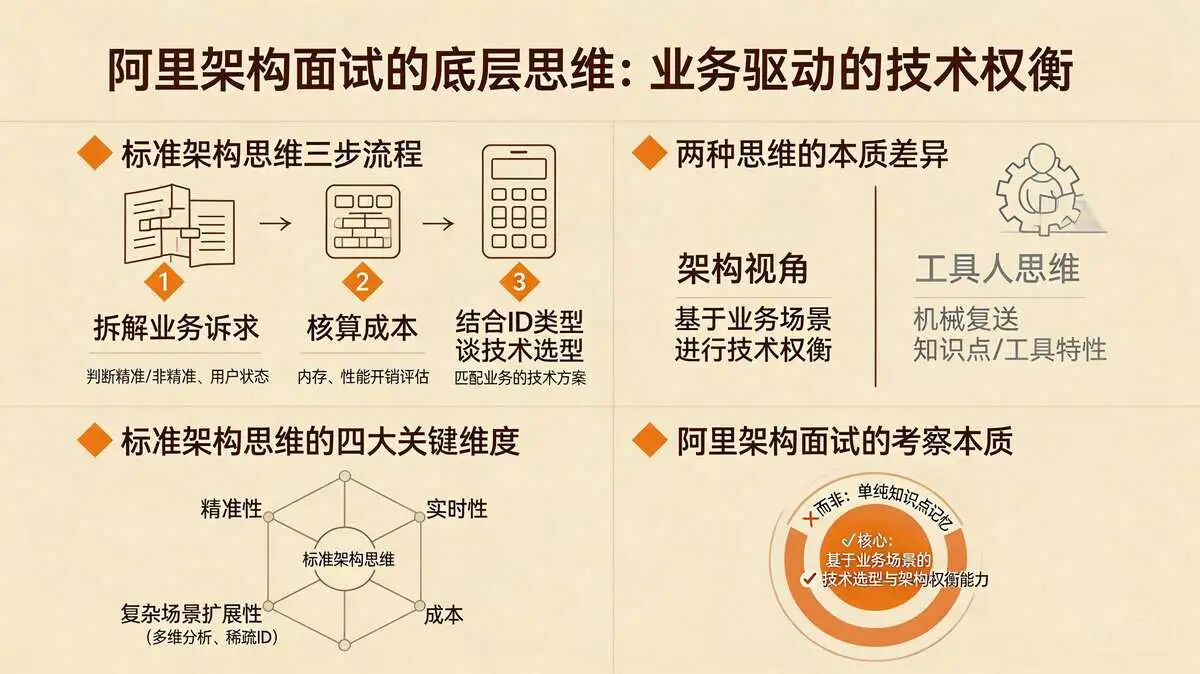
遇到这类面试题,核心思路是:先拆解业务诉求(精准/非精准、是否需要判断用户状态),再核算成本(内存、性能),最后结合ID类型谈技术选型。
这才是阿里想要的“架构视角”,而非只会背数据结构特性的“工具人”。
标准架构思维,兼顾了精准性、实时性、成本以及复杂场景(多维分析、稀疏ID)的扩展性。
面试考察本质:考察的是基于业务场景的技术选型与架构权衡能力,而非单纯的知识点记

 浙公网安备 33010602011771号
浙公网安备 33010602011771号